 动态住宅IP
动态住宅IP
 动态数据中心IP
动态数据中心IP
 独享数据中心IP
独享数据中心IP
 动态长效ISP
动态长效ISP
 静态住宅IP
静态住宅IP








 美国
美国
 英国
英国
 加拿大
加拿大
 泰国
泰国
 印度
印度
 韩国
韩国
 马来西亚
马来西亚
 印度尼西亚
印度尼西亚
 更多地区
更多地区








使用ip代理腾讯视频评论爬虫案例
2022-09-23
对于专业的爬虫工程师,掌握爬虫语言和ip代理使用代理商可以爬取不同网站的不同信息。今天我们来看看爬虫的具体案例。
腾讯视频的评论怎么爬?下面跟着IPIDEA看具体操作步骤:

打开腾讯视频,如火狐浏览器https://v.qq.com/x/cover/j6cgzhtkuonf6te.html
点击查看更多解释fiddler会有一个js文件:

里面的内容就是评论。
找到一条评论转码:
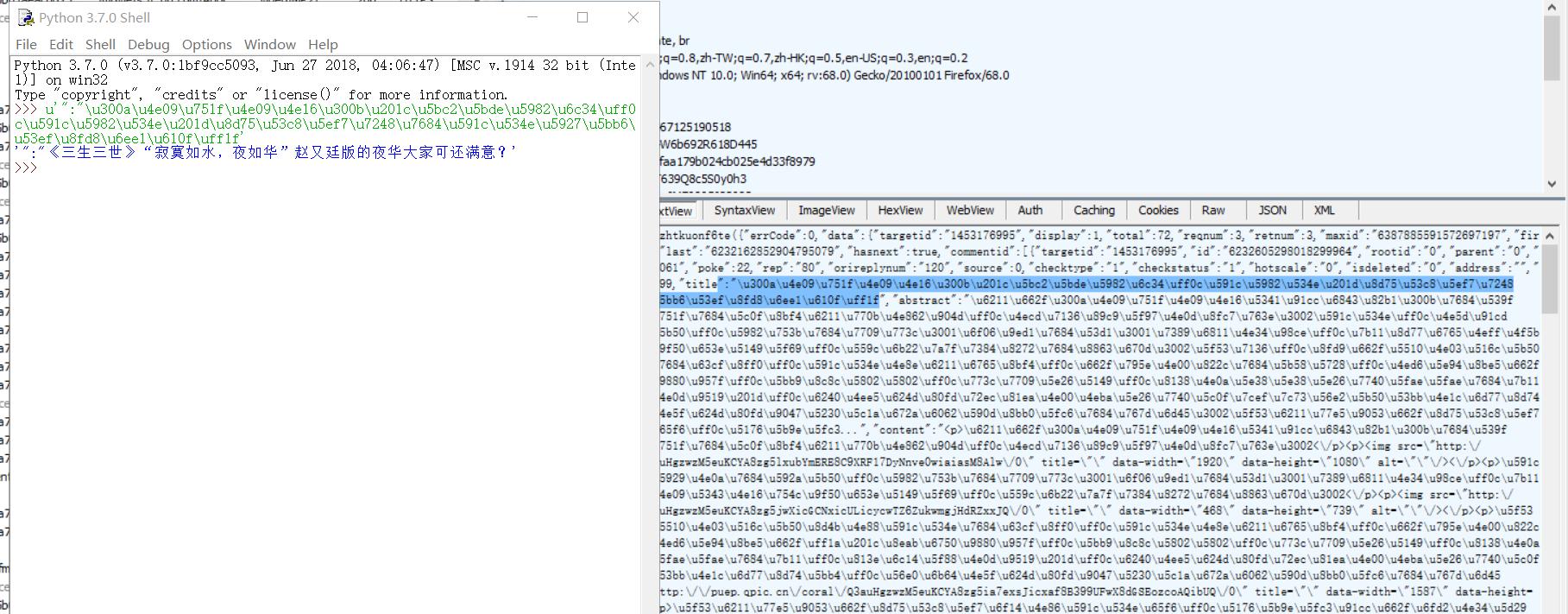
在火狐里ctrl+f看看有没有这条评论。
copy js文件的url。
点击查看更多评论,再触发一个json,copy url
分析两个url:

简化一下网页试试:https://video.coral.qq.com/filmreviewr/c/upcomment/j6cgzhtkuonf6te?reqnum=3&commentid=6227734628246412645
通过分析,我们可以知道j6cg……是视频id,reqnum是每次查看的评论数量,commentid是评论id
https://video.coral.qq.com/filmreviewr/c/upcomment/【vid】?reqnum=【num】&commentid=【cid】
单页评论爬虫
有一些特殊字符比如图片现在还不知道怎么处理……以后再说吧
import urllib.request
import re
from uaip import *
vid="j6cgzhtkuonf6te"
cid="6227734628246412645"
num="3" #每页提取3个
url="https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?reqnum="+num+"&commentid="+cid
data=ua_ip(url)
titlepat="title":"(.*?)","abstract":"
commentpat="content":"(.*?)",
titleall=re.compile(titlepat,re.S).findall(data)
commentall=re.compile(commentpat,re.S).findall(data)
# print(len(commentall))
for i in range(len(titleall)):
try:
print("评论标题是:"+eval("u"+titleall[i]+""))
print("评论内容是:"+eval("u"+commentall[i]+""))
print(---------------)
except Exception as err:
print(err)
翻页评论爬虫
查看网页源代码可以发现last:后面的内容为下一页的id
import urllib.request
import re
from uaip import *
vid="j6cgzhtkuonf6te"
cid="6227734628246412645"
num="3"
for j in range(10): #爬取1~10页内容
print("第"+str(j+1)+"页")
url = "https://video.coral.qq.com/filmreviewr/c/upcomment/" + vid + "?reqnum=" + num + "&commentid=" + cid
data = ua_ip(url)
titlepat = "title":"(.*?)","abstract":"
commentpat = "content":"(.*?)",
titleall = re.compile(titlepat, re.S).findall(data)
commentall = re.compile(commentpat, re.S).findall(data)
lastpat="last":"(.*?)"
cid=re.compile(lastpat,re.S).findall(data)[0]
for i in range(len(titleall)):
try:
print("评论标题是:" + eval("u" + titleall[i] + ""))
print("评论内容是:" + eval("u" + commentall[i] + ""))
print(---------------)
except Exception as err:
print(err)
对于短评(普通评论)方法类似,这里就不赘述了,看下面这个短评爬虫代码:
将https://video.coral.qq.com/varticle/1743283224/comment/v2?callback=_varticle1743283224commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6442954225602101929&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1566363507957
简化成:https://video.coral.qq.com/varticle/1743283224/comment/v2?orinum=10&oriorder=o&pageflag=1&cursor=6442954225602101929
import urllib.request
import re
from uaip import *
vid="1743283224"
cid="6442954225602101929"
num="5"
for j in range(10): #爬取1~10页内容
print("第"+str(j+1)+"页")
url="https://video.coral.qq.com/varticle/"+vid+"/comment/v2?orinum="+num+"&oriorder=o&pageflag=1&cursor="+cid
data = ua_ip(url)
commentpat = "content":"(.*?)"
commentall = re.compile(commentpat, re.S).findall(data)
lastpat="last":"(.*?)"
cid=re.compile(lastpat,re.S).findall(data)[0]
# print(len(gg))
# print(len(commentall))
for i in range(len(commentall)):
try:
print("评论内容是:" + eval("u" + commentall[i] + ""))
print(---------------)
except Exception as err:
print(err)
以上,我们就将腾讯视频的评论内容给抓取下来了,各位可以自己练习看看效果。
声明:本文来自网络投稿,不代表IPIDEA立场,若存在侵权、安全合规问题,请及时联系IPIDEA进行删除。
下一篇:如何防止账号关联ip代理访问?
 最新文章
最新文章
 热门文章
热门文章








